
Python 연습장
pycaret 개요 & classification 본문
pycaret (파이캐럿) 은 autoML 중 가장 유명한 라이브러리다. 사실 가장 유명한지는 모르겠지만 예제 같은 데에 가장 많이 나오는 것 같다.
autoML 이란 자동으로 머신러닝 모델을 구축해주는건데, 자동까지는 아니고 pycaret 에서 소개하는 구문과 같이 low code ML library 라고 생각하면 된다.
예를 들어 xgb, lightgbm, extratrees 등의 알고리즘을 이것저것 넣어서 성능을 평가해보고 모델별로 성능을 나열해서 그중에 가장 좋은 모델을 선택하고 그 다음 모델 최적화하는 과정을 단 몇 줄로 만들 수 있게 해준다. (지금 말한 과정은 두 줄로 가능)
코드가 복잡해지면 늪에 빠진다. 가장 간결한 코드가 가장 좋은 코드다. (물론 같은 성능을 낸다는 가정 아래)
파이썬 초보가 사용하기 좋은 툴이라고 하는데 초보의 범위가 어디까지인지는 모르겠으나 솔직히 쌩초보가 사용하기에는 적절하진 않은 것 같다. 정석 코드로 길게 써보고 그걸 줄여가는 과정을 연습을 해야 이해가 되지 지름길만 보면 다른 툴에서 응용이 어려울 것이다. 그리고 아무래도 한 번 더 가공해서 만들 툴이라서 자유도가 떨어지고 기존 툴보다는 자료가 적어서 여기서 뭘 더 할 수 있는지 알기 어렵다.
Pycaret 라이브러리 내에는 classification(분류), regression(회귀), clustering(군집), anomaly detection(이상감지), NLP(자연어처리), association rules(연관규칙), datasets(그냥 연습용 데이터셋) 등의 패키지가 있다.
time-series 가 예전에는 있었던 거 같은데 지금은 없다.
먼저 설치해보자. 커맨드/터미널창에 입력한다.
pip install pycaret
Classification 부터 하나씩 예제로 모델을 만들어보자.
jupyter notebook 에서 실행해야 evaluate model, interpret model 에서 제대로 결과를 확인할 수 있다.
(terminal) jupyter notebook
1. Data 불러오기
먼저 datasets 패키지로 예시 데이터를 불러온다.
pycaret 의 예시 데이터가 아닌 다른 데이터를 사용하려면 target 이 포함된 dataframe 을 불러오면 된다.
from pycaret.datasets import get_data
juice = get_data('juice')
# 데이터를 불러온다.
2. Data 전처리 (setup)
from pycaret.classification import *
# 분류 패키지의 모든 모듈을 임포트한다.
exp = setup(data = juice,
target = 'Purchase',
normalize = True,
normalize_method = 'minmax', # 기본은 zscore
transformation = True,
fold = 5, # 기본적으로 10 fold 로 training 한다.
fold_shuffle=True,
ignore_features = ['PriceDiff'], # 제외할 컬럼 (이거 너무 편하다!)
numeric_features = ['PriceCH','PriceMM'],
categorical_features = ['Store7'], # 지정하면 onehotencoding된다.
date_features = [], # 날짜 feature를 년월일시 로 바꿔서 onehotencoding 해준다.
silent = True, # setup 시 중간에 피쳐속성 확인하고 엔터 쳐줘야하는데 알아서 넘어가게 해준다.
session_id = 123, # random state number 지정
use_gpu = True, # gpu 사용 옵션
feature_selection = True,
feature_selection_method = 'classic', # or 'boruta'
# classic 은 permutation importance 기반이다.
fix_imbalance = True, # data imbalance 를 sampling method로 보정
fix_imbalance_method = imblearn.OverSampling.RandomOverSampler()
# 기본은 SMOTE
# custom_pipeline = pipe, preprocess =False
# 두 개는 세트, 사용자가 원하는 파이프라인을 구성할 수 있다.
)위 예시는 모델링하려고 만든 건 아니고 parameter 이 어떤 게 있고 뭔 뜻인지 나타낸 것이다.
pycaret 공식 홈페이지 튜토리얼 보면 setup(data = data, target='target') 하고 끝나는데 실제로는 그렇게 사용할 순 없다. 그저 pycaret 이 그만큼 간단히 쓸 수 있다는 걸 효과적으로 보여주기 위한 것일 뿐...
정형화된 툴을 만들어본 사람은 알겠지만 굉장히 제약적이어서 실제 데이터를 적용하려면 이렇게 옵션이 많이 들어갈 수 밖에 없다.
그렇다고 자유도가 높은건 아니지만 어쨌든 효과적인 방법들 위주로 구성했고 어느 정도 커스텀할 수 있도록 했다.
셋업할 때 계속 아래와 같이 에러가 발생했다.
AttributeError: 'Simple_Imputer' object has no attribute 'fill_value_categorical'scikit-learn 을 삭제했다 재설치해도 안되고 pycaret 을 재설치 해도 안되고.. 하도 안돼서 찾아보니 python 3.9에서는 지원이 안된단다.
3.6~3.8 까지만 지원하고 3.9 는 우분투만 지원한단다.
근데 분명히 내가 3.8로 설치했던 거 같은데 이상하다...
아무튼 3.9버전인걸 확인했고 터미널창에 conda install python==3.8 입력하여 다운그레이드 시켜줬다.
(패키지 처음부터 다시 설치해야해서 너무 귀찮다 ㅠㅠ)
pycaret 예시를 보면 패키지를 공통적으로 import * 로 불러온다.
이렇게 하면 같은 파일에서 classification과 anomaly detection을 같이 할 수 없다.
만약 같은 파일에서 두 개 종류이상의 모델링을 하려면
from pycaret import classification as clf, anomaly as an
이런식으로 불러와서 clf.setup( ~~) 으로 입력해야 한다.
normalize 는 기본은 False 고 method 기본은 z score 다. 거의 모든 데이터셋은 노멀라이즈 진행하니까 True 로 변경했다.
ignore_feature 는 데이터 중에서 안사용할 feature 골라내는 거다. 이건 진짜 유용하다. 그동안 list comprehension 길게 늘여쓰며 제외해왔는데 직관적으로 한번에 바로 제거할 수 있어서 편한다.
juice dataset 은 pycaret 에서 공식적으로 제공하는 데이터셋이라서 데이터 타입까지 잘 읽어들이겠지만 실제로는 다를 수 있으니 auto로 실행해보고 아니면 수동으로 설정해주면 된다. (확실히 pycaret 은 auto ml은 아니다. semi-auto ml 이다)
numeric_features, categorical features, date features 등으로 테이터 타입을 컬럼별로 지정한다.
categorical features 는 OneHotEncoding 으로 변환되고, date feature 는 연월일시로 바꿔서 OneHotEncoding 시켜준다.
참고로 catboost encoding 은 pycaret 에서는 불가하다. (pycaret 2.3.6 버전 기준)
custom pipeline 으로 해도 안되고 setup 후 강제로 데이터를 입히는 set_config('X_train', catboostencoded_data) 로도 안된다. set_config 까지는 먹지만 그 뒤에 create_model 이 안된다. 나는 오기로 적용해봤는데 사실 강제로 데이터를 입힐꺼면 pycaret 을 사용안하는게 더 간편하다.
Pycaret 을 하다보면 생각보다 되는 것도 많은데 생각보다 안되는 것도 참 많다. 그냥 feasiblity 보는 정도로만 활용하면 좋을 것 같다.
fix_imbalance 옵션을 활용해서 샘플링 옵션을 적용할 수 있다. 기본으로는 method 를 SMOTE 를 사용하는데 나는 SMOTE 적용했을 때 성능이 더 나빠지는 케이스가 더 많았어서 차라리 imblearn 의 random over sampler 를 사용한다.
어떤 method 를 사용하든 패키지에서 불러오는 모듈이라면 이 때 꼭 끝에 '()' 를 붙여줘야 한다 : RandomOverSampler()
setup 후 pycaret 에서 transformed 된 데이터 얻는 방법은 간단하다. get_config 를 사용하면 된다.
data_transformed = get_config('X')get_config('X_train'), get_config('y_train') 등을 활용하면 된다.
파이프라인이 어떻게 적용되었는지도 알수 있다. get_config('prep_pipe') 를 통해서 어떤 순서로 데이터가 어떻게 transformed 되었는지 확인 가능하다.
아래서 imputer 는 결측치를 대체하는 방법으로 from sklearn.impute import SimpleImputer 를 기본적으로 사용한다.
In[] : get_config('prep_pipe')
Out[] : Pipeline(memory=None,
steps=[('dtypes',
DataTypes_Auto_infer(categorical_features=['Store7'],
display_types=False,
features_todrop=['PriceDiff'],
id_columns=['Id'],
ml_usecase='classification',
numerical_features=['PriceCH', 'PriceMM'],
target='Purchase', time_features=[])),
('imputer',
Simple_Imputer(categorical_strategy='not_available',
fill_value_categorical...
('fix_perfect', Remove_100(target='Purchase')),
('clean_names', Clean_Colum_Names()),
('feature_select',
Advanced_Feature_Selection_Classic(ml_usecase='classification',
n_jobs=-1,
random_state=8139,
subclass='binary',
target='Purchase',
top_features_to_pick=0.19999999999999996)),
('fix_multi', 'passthrough'), ('dfs', 'passthrough'),
('pca', 'passthrough')],
verbose=False)
3. 모델 만들기
models() 를 입력하면 pycaret classification 에서 제공하는 알고리즘들을 보여준다.
logistic regression 같은 가장 기본적인 알고리즘부터 lightgbm, catboost, xgb 비교적 최근에 개발된 알고리즘까지 다양한 모델들을 제공한다.
여기서 테스트해볼 모델들을 생각해두고 compare models 를 실행한다.
models()
실행해보니 xgboost 와 catboost 가 리스트에 없다.
아까 python 3.9에서 3.8로 내리면서 설치를 안해서 없는거고 xgboost catboost 설치해주니까 다시 models에 추가된다.
없다고 나처럼 당황하지 마시고 pip list 에서 패키지 설치 여부 먼저 확인해보시길.
compare_models()그냥 이렇게 실행해도 되지만 데이터가 큰 경우에는 모든 모델을 다 비교해보는 게 시간 낭비일 수 있다.
include 옵션, 혹은 exclude 옵션을 통해서 평가해볼 모델을 선택할 수 있다.
xgboost 나 catboost 같은 경우는 시간이 비교적 오래걸리므로 데이터가 크면 먼저 다른 모델부터 비교해보고 나중에 추가하자.
best = compare_models(include = ['lr','lightgbm','rf'], sort='F1')
best = compare_models(exclude = ['catboost'], sort='F1')
best3 = compare_models( sort='Accuracy', n_select = 3, budget_time = 0.5)compare models 는 결과값으로 best 모델을 반환해준다. 그 기준은 sort 로 정할 수 있다.
budget_time 은 학습 시간에 제약을 주는 거다.
너무 오랜 시간이 걸릴 경우를 방지하기 위해 학습 제한 시간을 설정해줄 수 있다.
제한 시간 설정 시 시간이 오래 걸리는 catboost, xgboost 등의 결과는 안나올 수 있다.
clf = create_model('xgboost')best 모델을 compare_models 를 통해서 받아올 수 있고,
직접 알고리즘을 선택하여 create models 로 모델을 만들 수 있다.
옵션으로는 return_train_score = True, cross_validation = False 등이 있다.
데이터가 많은 경우는 cross_validation False 로 주고 돌리는게 시간 절약된다.
tuned_clf = tune_model(clf, optimize = 'F1')hyper parameter 를 자동으로 튜닝해주는 모듈이다.
전처리 과정(setup)과 tune_model 이 pycaret 에서 가장 편한 것 같다.
optimize 파라미터를 통해서 accuracy, recall, F1 등 어떤 score 가 가장 좋게 튜닝할 것인지 결정해준다.
4. 평가 결과 확인하기
plot_model 을 통해서 confusion matrix, auc curve, feature importance 등을 확인할 수 있다.
plot_model(tuned_clf, plot = 'confusion_matrix')
plot = 'auc' / plot = 'feature' / plot = 'class_report' 처럼 plot 옵션으로 파라미터를 변경해준다.
default 로 나오는 값은 test data 고 train data 를 확인하고 싶으면 use_train_data = True 를 추가한다.
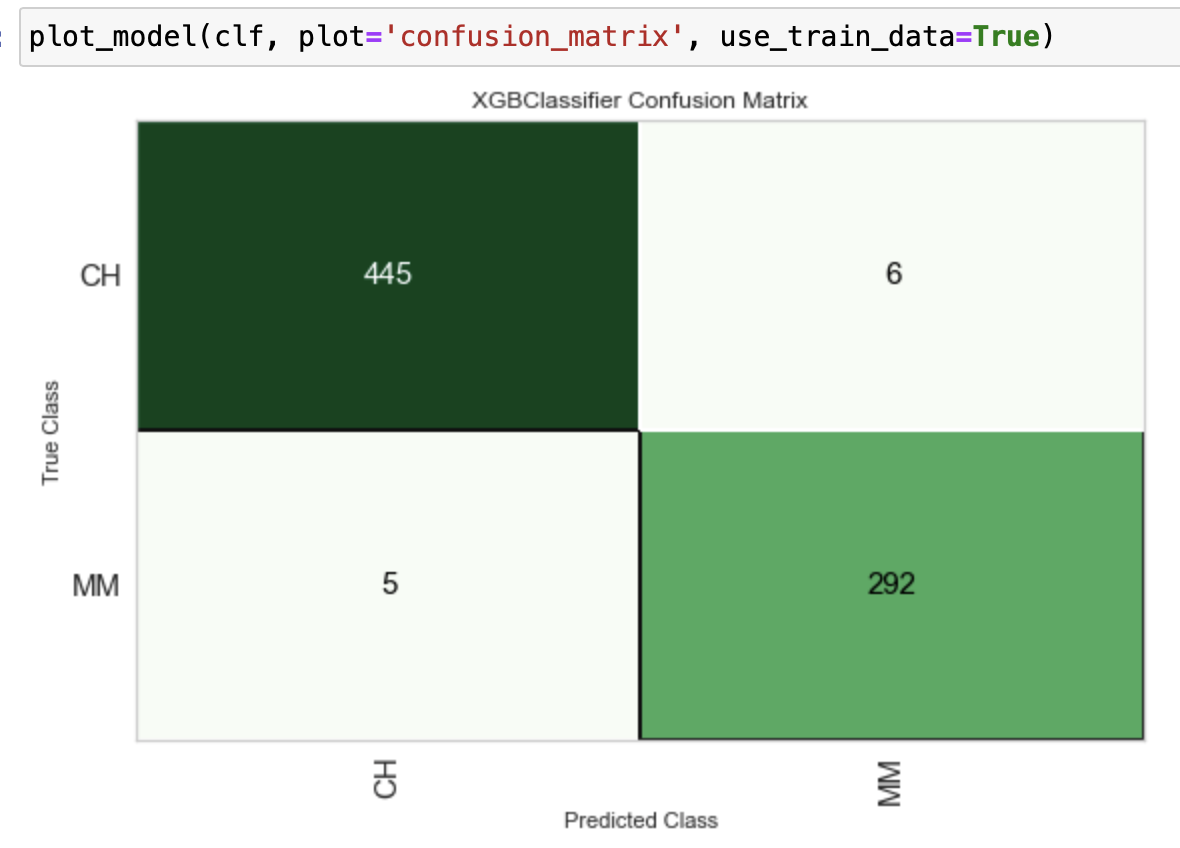
저렇게 plot 옵션을 하나씩 주지 말고 evaluate_model 로 성능을 확인하면 편하다.
하지만 data 가 많으면 버벅거려서 잘 사용 안한다.
evaluate_model(clf)
plot model 과 마찬가지로 use_train_data = True 옵션을 사용해서 train set 를 평가 결과를 확인할 수 있다.
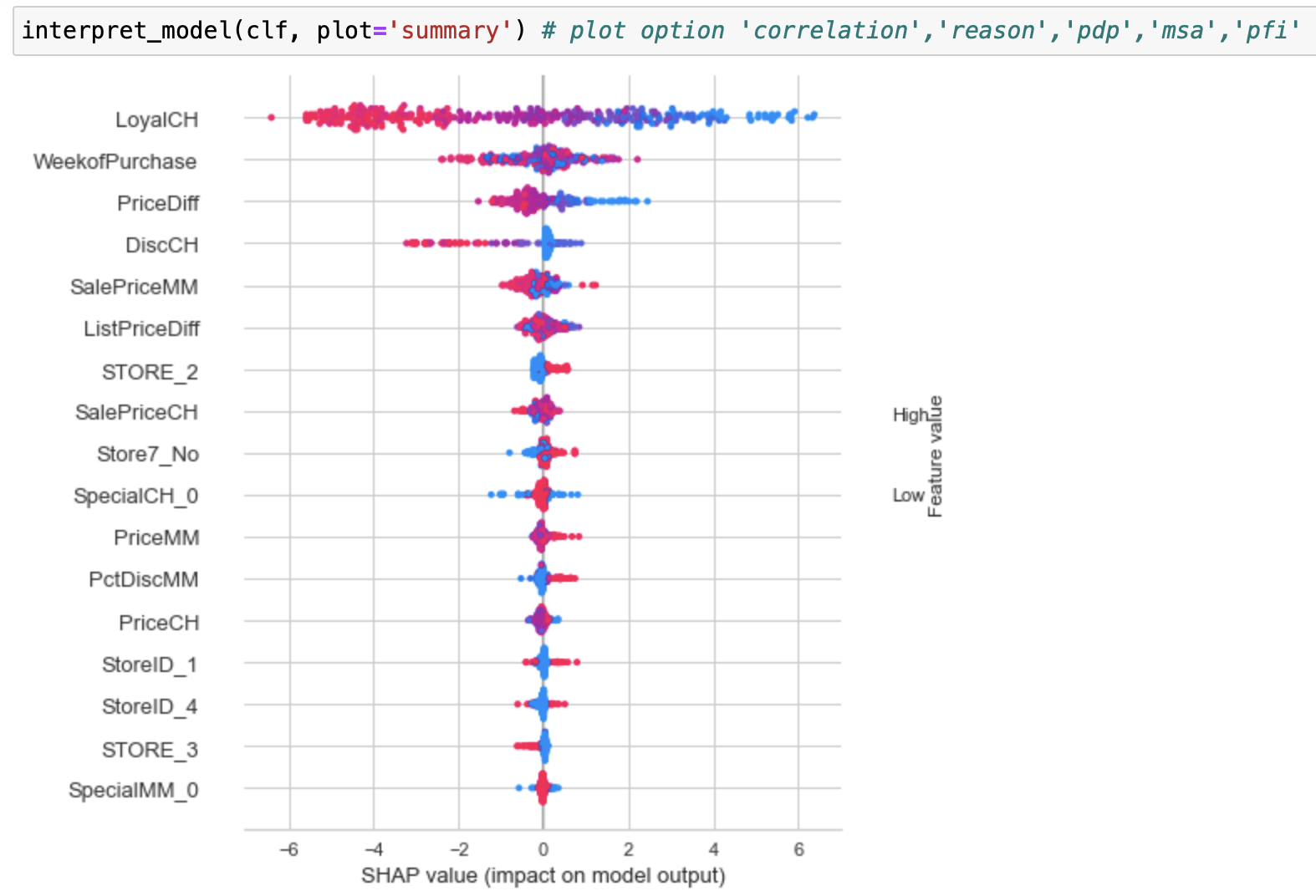
5. 모델 해석하기
pycaret 에서 interpret model 은 shap 기반이기 때문에 shap 이 안 깔려있는 경우는 !pip install shap 으로 설치해준다.
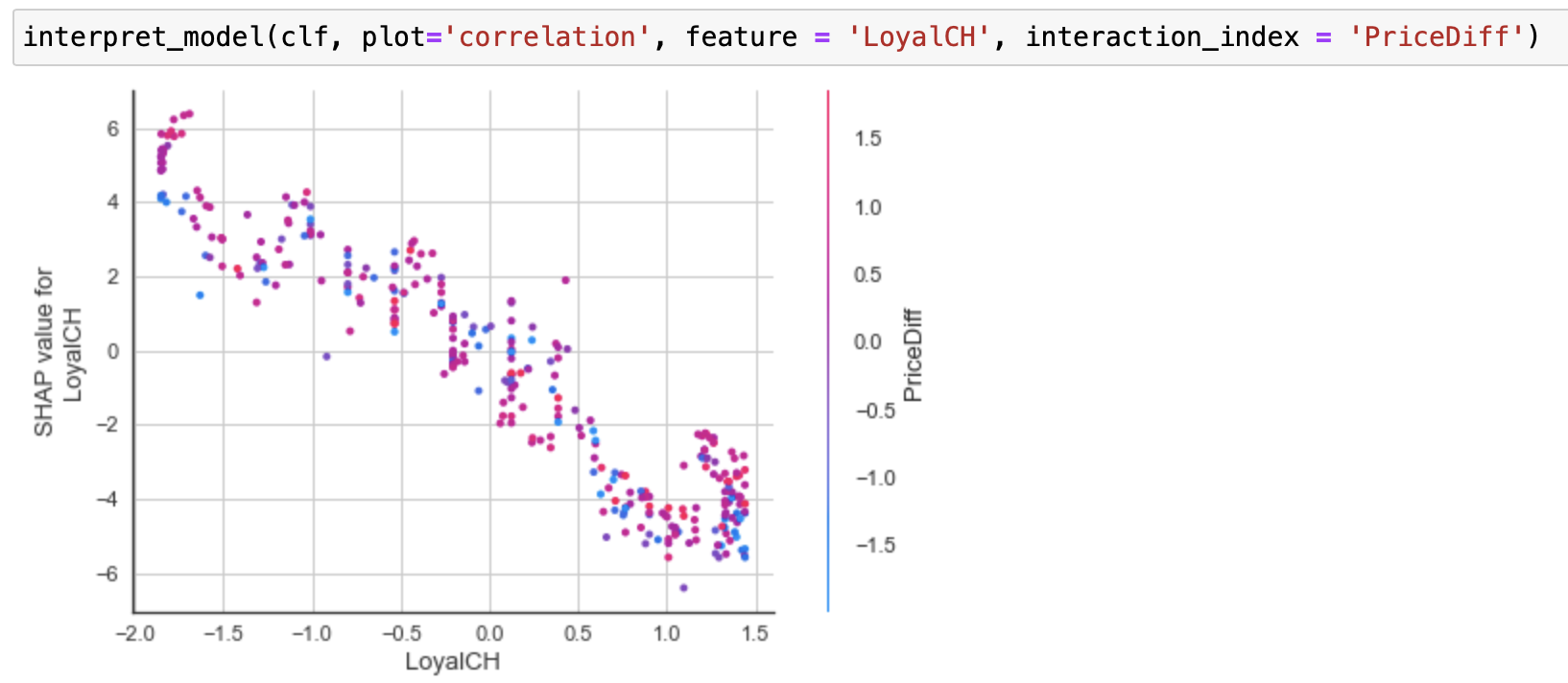
dependence plot 을 보려면 plot 옵션을 correlation 으로 설정하면 되는데, 이 때 상관 관계를 볼 두 개 변수를 지정하는 파라미터는 feature 와 interaction_index 다.
setup 이나 tune model 은 많이 간편해지는데 interpret 는 크게 간단해지지는 않는다.
shap 은 그렇게 복잡하지 않으므로 그냥 import shap 해서 모델 해석하는게 더 편한 것 같다.
6. 종합 + 모델로 예측하기
위에서 모델을 예측하고 성능평가를 하는 거까지 종합한 코드다. 한페이지도 안되는 완전 low code 다.
위에서 설명 안된게 3가지 있는데,
unseen data 를 만들기 위한 sample 함수,
떼어낸 데이터 셋을 predict할 때 사용하는 predict_model 함수,
그리고 predict 성능을 확인하는 check_metrics 다.
from pycaret.datasets import get_data
from pycaret.classification import *
juice = get_data('juice')
data = juice.sample(frac = 0.2, random_state=123)
data_unseen = juice.drop(data.index)
exp = setup(data = data, target = 'Purchase', normalize = True, silent = True)
compare_models()
clf = create_model('xgboost')
# clf = compare_models() 로도 가능하지만 interpret model 이 tree 기반만 가능하므로 일부러 xgboost 로 고정함
plot_model(clf, plot='confusion_matrix')
tuned_clf = tune_model(clf, optimize= 'F1')
plot_model(tuned_clf, plot='confusion_matrix')
interpret_model(tuned_clf, plot='summary')
pred_unseen = predict_model(tuned_model, data = data_unseen)
from pycaret.utils import check_metric
check_metric(pred_unseen['Purchase'], pred_unseen['Label'], metric = 'F1')
이 외에 finalize_model 함수는 unseen data(holdout set) 까지 모두 포함하여 학습을 시켜서 성능을 최대로 올릴 수 있도록 하고,
최종적으로 이 모델을 저장하는 save_model 함수도 있다.
하지만 앞에서도 말했듯이 pycaret 은 가능성을 보는 정도만 적절하기 때문에 굳이 필요치 않다고 판단해서 제외했다.
결론적으로 pycaret 은 제한적이지만 굉장히 좋은 라이브러리다. 아주 깔끔하다.
원래 pycaret의 regression, clustering 등등 모든 패키지들을 정리하고 싶었는데 classification 하나만 정리하는 데도 꽤 힘들었다.
오늘은 이쯤에서 마무리하고 다음에 시간되면 추가로 정리해야겠다.
'코딩' 카테고리의 다른 글
| shap 이론 (0) | 2022.03.29 |
|---|---|
| clustering - kmeans (0) | 2022.03.21 |
| shap 의 colormap 으로 colorbar 그리기 (0) | 2022.03.14 |
| jupyter 설치 사용 (0) | 2022.03.13 |
| 파이썬에서 샘플dataset을 가져오는 4가지 방법 (0) | 2022.02.22 |


