
Python 연습장
파이썬에서 샘플dataset을 가져오는 4가지 방법 본문
파이썬에서 샘플 데이터를 다운받는 방법은 다양하다. 기본적으로 머신러닝을 하는 사람들은 모두 사이킷런 라이브러리를 사용하기 때문에 나는 사이킷런에서 데이터 로드하는 걸 선호했는데, 데이터셋이 한정적이라서 아쉬웠다.
그래서 좀 더 다양한 샘플데이터를 확인하고자 다른 방법을 찾아봤고, 여기에 4가지 샘플데이터 로드 방법을 소개하고자 한다.
1. sklearn.datasets
먼저 사이킷런에서 데이터를 불러오는 방법이다.
import pandas as pd
from sklearn.datasets import load_boston
data_func = load_boston()
df = pd.DataFrame(data = data_func.data, columns = data_func.feature_names)
df['target'] = data_func.target
print(df.head())load_boston 외에도
load_iris, load_diabetes, load_digits, load_linnerud, load_wine, load_breast_cancer
등을 같은 방식으로 불러올 수 있다.
이 밖에 dataset 을 확인하려면 datasets 패키지가 가지고 있는 모듈을 확인해보면 된다.
dir 함수로 아래와 같이 확인할 수 있다.
from sklearn import datasets
print( dir(datasets) )fetch_20newsgroups, fetch_20newsgroups_vectorized, fetch_california_housing, fetch_covtype,
fetch_kddcup99, fetch_lfw_pairs, fetch_lfw_people, fetch_olivetti_faces, fetch_openml, fetch_rcv1,
fetch_species_distributions, load_boston, load_breast_cancer, load_diabetes, load_digits, load_files,
load_iris, load_linnerud, load_sample_image, load_sample_images, load_svmlight_file, load_svmlight_files, load_wine
사실 fetch~ 데이터셋들은 잘 모르겠는데 하나씩 실습해봐야겠다.
2. seaborn load_dataset
그 다음은 seaborn 라이브러리에서 불러오는 방법이다.
import seaborn as sns
print(sns.get_dataset_names())
#['anagrams', 'anscombe', 'attention', 'brain_networks', 'car_crashes',
# 'diamonds', 'dots', 'exercise', 'flights', 'fmri', 'gammas',
# 'geyser', 'iris', 'mpg', 'penguins', 'planets', 'taxis', 'tips', 'titanic']
df = sns.load_dataset('dots')sklearn 보다 조금 더 간단하게 불러올 수 있다.
3. pydataset
pydataset은 흔한 패키지는 아니라 보통은 안깔려있을 것 같다. 커맨드창에서 pip install pydataset 으로 먼저 install 해준다.
dataset 전용 패키지인 만큼 데이터셋이 굉장히 많다. 한번 불러와서 몇 개나 있는지 보자.
import pandas as pd
from pydataset import data
datalist = data()
print(datalist.head())
# dataset_id title
# 0 AirPassengers Monthly Airline Passenger Numbers 1949-1960
# 1 BJsales Sales Data with Leading Indicator
# 2 BOD Biochemical Oxygen Demand
# 3 Formaldehyde Determination of Formaldehyde
# 4 HairEyeColor Hair and Eye Color of Statistics Students
print(datalist.shape)
# (757, 2)
무려 757개나 있다.
불러오는 방법은 data( dataset_id ) 로 가지고 오면 된다.
근데 가장 맨 위에 있는 AirPassengers 를 가지고 와보니 feature가 하나밖에 없다. 내가 하고자하는 머신러닝 모델을 만들기에는 데이터 수가 부족하다. 다른 것들도 샘플링으로 확인해보니, 한 개 밖에 없는게 꽤 많았다.
그래서 pydataset 에 있는 dataset 중에 column이 10개 이상 되는 것들을 다시 추려봤다.
df_data = pd.DataFrame()
for i, dataset_id in enumerate(datalist.dataset_id):
dataset = data(dataset_id)
df_data.loc[i, 'dataset_name'] = dataset_id
df_data.loc[i, 'row_num'] = dataset.shape[0]
df_data.loc[i, 'column_num'] = dataset.shape[1]
print(len(df_data.loc[df_data.column_num > 10]))
# 127모두 127개다. 어떤 데이터셋이 있는지 확인해보자.
print(df_data.loc[df_data.column_num > 10].head())
# dataset_name row_num column_num
# 20 USJudgeRatings 43.0 12.0
# 34 crimtab 42.0 22.0
# 47 mtcars 32.0 11.0
# 68 volcano 87.0 61.0
# 108 nuclear 32.0 11.0이중에 nuclear 를 샘플로 불러와 봤다.
df = data('nuclear')
print(df.head())
# cost date t1 t2 cap pr ne ct bw cum.n pt
# 1 460.05 68.58 14 46 687 0 1 0 0 14 0
# 2 452.99 67.33 10 73 1065 0 0 1 0 1 0
# 3 443.22 67.33 10 85 1065 1 0 1 0 1 0
# 4 652.32 68.00 11 67 1065 0 1 1 0 12 0
# 5 642.23 68.00 11 78 1065 1 1 1 0 12 0
확인해보고 싶어서 pydataset의 데이터셋별 컬럼개수를 히스토그램으로 그려봤다.
df_data.column_num.hist(bins =range(40) )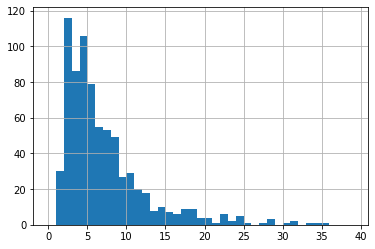
컬럼수가 적은 데이터셋이 많은 점은 조금 아쉽지만 그래도 데이터셋이 다양해서 굉장히 만족스럽다.
4. statsmodel
샘플 데이터셋을 불러올 수 있는 또한가지 방법은 statsmodel 이다.
import statsmodels.api as sm
print ( dir(sm.datasets) )
# 'anes96', 'cancer', 'ccard', 'check_internet', 'china_smoking', 'clear_data_home', 'co2',
# 'committee', 'copper', 'cpunish', 'danish_data', 'elnino', 'engel', 'fair', 'fertility',
# 'get_data_home', 'get_rdataset', 'grunfeld', 'heart', 'interest_inflation', 'longley',
# 'macrodata', 'modechoice', 'nile', 'randhie', 'scotland', 'spector', 'stackloss',
# 'star98', 'statecrime', 'strikes', 'sunspots', 'test', 'utils', 'webuse'
df = sm.datasets.elnino.load_pandas()['data']
print(df.head())
# YEAR JAN FEB MAR APR ... AUG SEP OCT NOV DEC
# 0 1950.0 23.11 24.20 25.37 23.86 ... 20.15 19.67 20.03 20.02 21.80
# 1 1951.0 24.19 25.28 25.60 25.37 ... 22.32 21.44 21.77 22.33 22.89
# 2 1952.0 24.52 26.21 26.37 24.73 ... 20.02 19.63 20.40 20.77 22.39
# 3 1953.0 24.15 26.34 27.36 27.03 ... 21.45 21.25 20.95 21.60 22.44
# 4 1954.0 23.02 25.00 25.33 22.97 ... 19.33 18.95 19.11 20.27 21.30불러오는 구문이 좀 길어서 이것보다는 pydataset 을 더 자주 사용하게 될 것 같다.
'코딩' 카테고리의 다른 글
| shap 의 colormap 으로 colorbar 그리기 (0) | 2022.03.14 |
|---|---|
| jupyter 설치 사용 (0) | 2022.03.13 |
| 함수 return 값이 많을 경우 (0) | 2022.02.15 |
| 분류(classification)의 평가지표와 confusion matrix (0) | 2022.01.21 |
| category_encoders (1) (0) | 2022.01.20 |

